Update: @xukai92’s Julia Implementation can be found here.
Reconstructing The Latent Code Is Not Enough To Avoid Mode Collapsing
Learning In Implicit Models
Deep generative models that do not induce a density function that can be tractably computed, but rather provide a simulation procedure to generate new data points are called implicit statistical models. Generative adversarial networks (GANs) are an attractive such method, which have seen promising recent successes. GANs train two deep networks in concert: a generator network that maps random noise, usually drawn from a multi-variate Gaussian, to data items; and a discriminator network that estimates the likelihood ratio of the generator network to the data distribution, and is trained using an adversarial principle
More formally, let denote the training data, where each is drawn from an unknown distribution . A GAN is a neural network that maps representation vectors , typically drawn from a standard normal distribution, to data items . Because this mapping defines an implicit probability distribution, training is accomplished by introducing a second neural network , called a discriminator, whose goal is to distinguish samples from the generator to those from the data. The parameters of these networks are estimated by solving the minimax problem
,
where indicates an expectation over the standard normal , indicates an expectation over the empirical distribution, and denotes the sigmoid function. At the optimum, in the limit of infinite data and arbitrarily powerful networks, we will have , where is the density that is induced by running the network on normally distributed input, and hence that .
Mode Collapsing Issue in GANs
Despite an enormous amount of recent work, GANs are notoriously fickle to train, and it has been observed that they often suffer from mode collapse, in which the generator network learns how to generate samples from a few modes of the data distribution but misses many other modes, even though samples from the missing modes occur throughout the training data.
That is samples from capture only a few of the modes of . An intuition behind why mode collapse occurs is that the only information that the objective function provides about is mediated by the discriminator network . For example, if is a constant, then is constant with respect to , and so learning the generator is impossible. When this situation occurs in a localized region of input space, for example, when there is a specific type of image that the generator cannot replicate, this can cause mode collapse.
VEEGAN
The main idea of VEEGAN is to introduce a second network that we call the reconstructor network which is learned both to map the true data distribution to a Gaussian and to approximately invert the generator network.
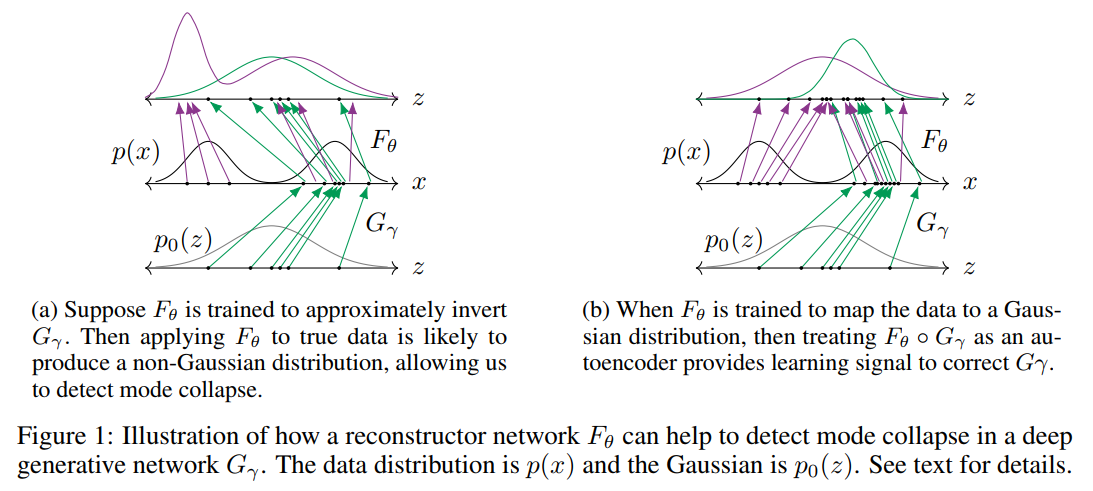
To understand why this might prevent mode collapse, consider the example in Figure 1. In both columns of the figure, the middle vertical panel represents the data space, where in this example the true distribution is a mixture of two Gaussians. The bottom panel depicts the input to the generator, which is drawn from a standard normal distribution , and the top panel depicts the result of applying the reconstructor network to the generated and the true data. The arrows labeled show the action of the generator. The purple arrows labelled show the action of the reconstructor on the true data, whereas the green arrows show the action of the reconstructor on data from the generator. In this example, the generator has captured only one of the two modes of . The difference between Figure 1a and 1b is that the reconstructor networks are different.
First, let us suppose (Figure 1a) that we have successfully trained so that it is approximately the inverse of . As we have assumed mode collapse however, the training data for the reconstructor network does not include data items from the forgotten” mode of therefore the action of on data from that mode is ill-specified. This means that is unlikely to be Gaussian and we can use this mismatch as an indicator of mode collapse.
Conversely, let us suppose (Figure 1b) that is successful at mapping the true data distribution to a Gaussian. In that case, if mode collapses, then will not map all back to the original and the resulting penalty provides us with a strong learning signal for both and .
Therefore, the learning principle for VEEGAN will be to train to achieve both of these objectives simultaneously. Another way of stating this intuition is that if the same reconstructor network maps both the true data and the generated data to a Gaussian distribution, then the generated data is likely to coincide with true data. To measure whether approximately inverts , we use an autoencoder loss. More precisely, we minimize a loss function, like loss between and . To quantify whether maps the true data distribution to a Gaussian, we use the cross entropy between and . This boils down to learning and by minimising the sum of these two objectives, namely
While this objective captures the main idea of our paper, it cannot be easily computed and minimised. We next transform it into a computable version below.
The proofs for the not-so-obvious inequalities are in the appendix of the paper. But essentially we start by establishing that,
where,
Here all expectations are taken with respect to the joint distribution The second term does not depend on or , and is thus a constant, because does neither depends on them nor on . The function denotes a loss function in representation space , such as loss. The third term is then an autoencoder in representation space.
In this case, we cannot optimize directly, because the KL divergence depends on a density ratio which is unknown, both because is implicit and also because is unknown. We estimate this ratio using a discriminator network which we will train to encourage,
This allows us to estimate as, .
We train the discriminator network using, .
Algorithm 1 below provides the exact procedural flow.

VEEGAN and VAE+GAN
Unlike other adversarial methods that train reconstructor networks, the noise autoencoder dramatically reduces mode collapse. Unlike recent adversarial methods that also make use of a data autoencoder, VEEGAN autoencodes noise vectors rather than data items. This is a significant difference, because choosing an autoencoder loss for images is problematic, but for Gaussian noise vectors, an loss is entirely natural. Experimentally, on both synthetic and real-world image data sets, we find that VEEGAN is dramatically less susceptible to mode collapse, and produces higher-quality samples, than other state-of-the-art methods.
Experiments
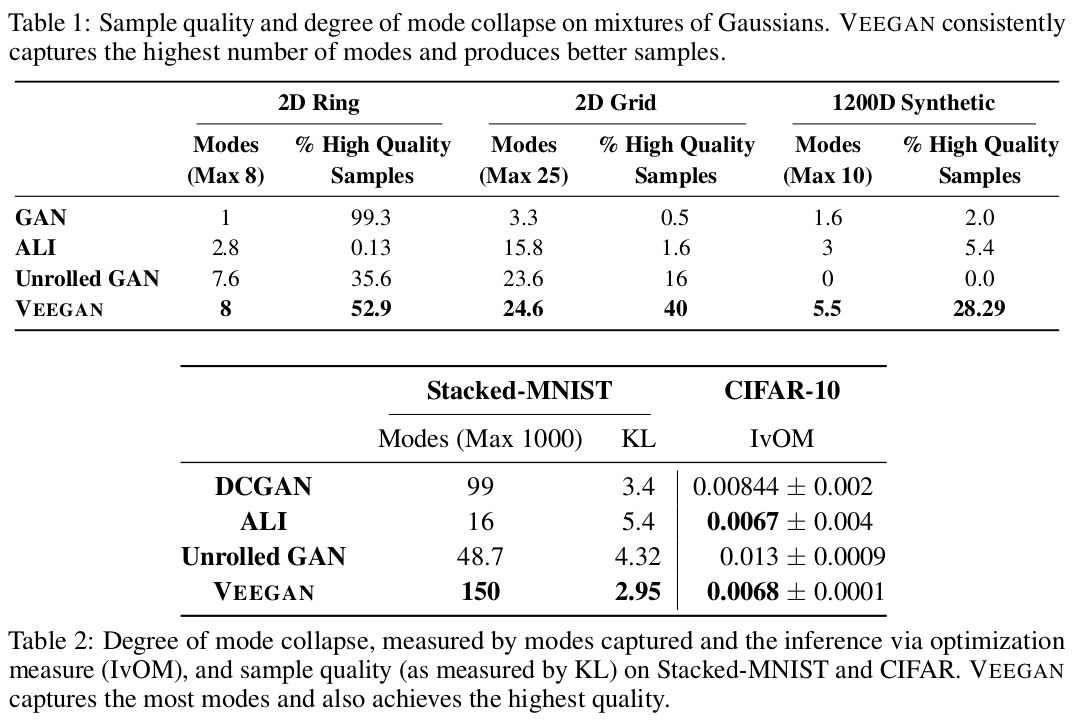 We comapre VEEGAN to three competing methods (GAN/DCGAN, ALI, Unrolled GAN) of training GANs on a large number of synthetic and real image datasets. As shown in talbe 1 and 2, VEEGAN is able to consistently recover more modes than all the other methods. The follwoing sections provide details of the individual expertiments.
We comapre VEEGAN to three competing methods (GAN/DCGAN, ALI, Unrolled GAN) of training GANs on a large number of synthetic and real image datasets. As shown in talbe 1 and 2, VEEGAN is able to consistently recover more modes than all the other methods. The follwoing sections provide details of the individual expertiments.
Synthetic Dataset
 Mode collapse can be accurately measured on synthetic datasets, since the true distribution and its modes are known. In this section we compare all four competing methods on three synthetic datasets of increasing difficulty: a mixture of eight 2D Gaussian distributions arranged in a ring, a mixture of twenty-five 2D Gaussian distributions arranged in a grid and a mixture of ten 700 dimensional Gaussian distributions embedded in a 1200 dimensional space. This mixture arrangement was chosen to mimic the higher dimensional manifolds of natural images.
Mode collapse can be accurately measured on synthetic datasets, since the true distribution and its modes are known. In this section we compare all four competing methods on three synthetic datasets of increasing difficulty: a mixture of eight 2D Gaussian distributions arranged in a ring, a mixture of twenty-five 2D Gaussian distributions arranged in a grid and a mixture of ten 700 dimensional Gaussian distributions embedded in a 1200 dimensional space. This mixture arrangement was chosen to mimic the higher dimensional manifolds of natural images.
To quantify the mode collapsing behavior we report two metrics: We sample points from the generator network, and count a sample as high quality, if it is within three standard deviations of the nearest mode, for the 2D dataset, or within 10 standard deviations of the nearest mode, for the 1200D dataset.Then, we report the number of modes captured as the number of mixture components whose mean is nearest to at least one high quality sample. We also report the percentage of high quality samples as a measure of sample quality. We generate 2500 samples from each trained model and average the numbers over five runs. For the unrolled GAN, we set the number of unrolling steps to five as suggested in the authors’ reference implementation.
Stacked MNIST
 Stacked MNIST dataset, a variant of the MNIST data is specifically designed to increase the number of discrete modes.The data is synthesized by stacking three randomly sampled MNIST digits along the color channel resulting in a 28x28x3 image. We now expect 1000 modes in this data set, corresponding to the number of possible triples of digits. As the true locations of the modes in this data are unknown, the number of modes are estimated using a trained classifier. We used a total of $26000$ samples for all the models and the results are averaged over five runs. As a measure of quality, we also report the KL divergence between the generator distribution and the data distribution.
Stacked MNIST dataset, a variant of the MNIST data is specifically designed to increase the number of discrete modes.The data is synthesized by stacking three randomly sampled MNIST digits along the color channel resulting in a 28x28x3 image. We now expect 1000 modes in this data set, corresponding to the number of possible triples of digits. As the true locations of the modes in this data are unknown, the number of modes are estimated using a trained classifier. We used a total of $26000$ samples for all the models and the results are averaged over five runs. As a measure of quality, we also report the KL divergence between the generator distribution and the data distribution.
CIFAR
 For CIFAR we use a metric introduced by Metz et al. (2017), which we will call the inference via optimization metric (IvOM). The idea behind this metric is to compare real images from the test set to the nearest generated image; if the generator suffers from mode collapse, then there will be some images for which this distance is large. To quantify this, we sample a real image from the test set, and find the closest image that the GAN is capable of generating, i.e. optimizing the loss between and generated image with respect to . If a method consistently attains low MSE, then it can be assumed to be capturing more modes than the ones which attain a higher MSE. We will also evaluate sample quality visually.
For CIFAR we use a metric introduced by Metz et al. (2017), which we will call the inference via optimization metric (IvOM). The idea behind this metric is to compare real images from the test set to the nearest generated image; if the generator suffers from mode collapse, then there will be some images for which this distance is large. To quantify this, we sample a real image from the test set, and find the closest image that the GAN is capable of generating, i.e. optimizing the loss between and generated image with respect to . If a method consistently attains low MSE, then it can be assumed to be capturing more modes than the ones which attain a higher MSE. We will also evaluate sample quality visually.
CelebA
 We tried the CIFAR setup for VEEGAN on the celebA dataset without any further tuning and as shown in the figure above it managed to generate high quality faces.
We tried the CIFAR setup for VEEGAN on the celebA dataset without any further tuning and as shown in the figure above it managed to generate high quality faces.
Inference
 While not the focus of this work, our method can also be used for inference as in the case of ALI and BiGAN models. Figure 4 shows an example of inference on MNIST. The top row samples are from the dataset. We extract the latent representation vector for each of the real images by running them through the trained reconstructor and then use the resulting vector in the generator to get the generated samples shown in the bottom row of the figure.
While not the focus of this work, our method can also be used for inference as in the case of ALI and BiGAN models. Figure 4 shows an example of inference on MNIST. The top row samples are from the dataset. We extract the latent representation vector for each of the real images by running them through the trained reconstructor and then use the resulting vector in the generator to get the generated samples shown in the bottom row of the figure.
Acknowledgement
We thank Martin Arjovsky, Nicolas Collignon, Luke Metz, Casper Kaae Sønderby, Lucas Theis, Soumith Chintala, Stanisław Jastrz˛ebski, Harrison Edwards and Amos Storkey for their helpful comments. We would like to specially thank Ferenc Huszár for insightful discussions and feedback.